 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Has AI Come in Liver Fibrosis Staging? A Large-Scale Real-World Dataset and Benchmark
May 25, 2026Despite years of methodological progress, how far AI has come in liver fibrosis staging has never been systematically evaluated under the heterogeneous, multi-center conditions that define clinical practice. To address this gap, we introduce LiFS, a large-scale dataset and benchmark derived from the MICCAI 2025 CARE-Liver challenge, comprising 610 patients across multiple centers and scanners with multi-sequence MRI. To the best of our knowledge, LiFS is the first benchmark providing complete gadoxetic acid-enhanced sequences with histopathology-confirmed annotations from diverse real-world scanners. Through systematic evaluation of 9 independently developed methods selected from 96 registered teams against in-cohort radiologist reference results, our findings address how far current AI has progressed toward clinical-level liver fibrosis staging from three complementary perspectives. First, against radiologists, the best AI methods were broadly comparable to the senior radiologist and significantly exceeded the junior radiologist in selected settings, while median AI performance generally approached junior-radiologist levels. Second, from a data perspective, cross-center heterogeneity, label imbalance, and contrast-enhanced sequence variability emerge as the dominant challenges for AI methods. Third, from a technical perspective, methodological design choices, including spatial registration, input dimensionality, multi-modal fusion strategy, and backbone architecture, appear to modulate cross-center robustness, although no single choice alone closes the gap. Overall, LiFS provides a rigorous real-world benchmark for positioning the current state of AI in liver fibrosis staging and for enabling future research on the key challenges that limit clinically reliable deployment.
Liver Fibrosis Quantification and Analysis: The LiQA Dataset and Baseline Method
Dec 22, 2025Liver fibrosis represents a significant global health burden, necessitating accurate staging for effective clinical management. This report introduces the LiQA (Liver Fibrosis Quantification and Analysis) dataset, established as part of the CARE 2024 challenge. Comprising $440$ patients with multi-phase, multi-center MRI scans, the dataset is curated to benchmark algorithms for Liver Segmentation (LiSeg) and Liver Fibrosis Staging (LiFS) under complex real-world conditions, including domain shifts, missing modalities, and spatial misalignment. We further describe the challenge's top-performing methodology, which integrates a semi-supervised learning framework with external data for robust segmentation, and utilizes a multi-view consensus approach with Class Activation Map (CAM)-based regularization for staging. Evaluation of this baseline demonstrates that leveraging multi-source data and anatomical constraints significantly enhances model robustness in clinical settings.
MERIT: Multi-view Evidential learning for Reliable and Interpretable liver fibrosis sTaging
May 05, 2024



Accurate staging of liver fibrosis from magnetic resonance imaging (MRI) is crucial in clinical practice. While conventional methods often focus on a specific sub-region, multi-view learning captures more information by analyzing multiple patches simultaneously. However, previous multi-view approaches could not typically calculate uncertainty by nature, and they generally integrate features from different views in a black-box fashion, hence compromising reliability as well as interpretability of the resulting models. In this work, we propose a new multi-view method based on evidential learning, referred to as MERIT, which tackles the two challenges in a unified framework. MERIT enables uncertainty quantification of the predictions to enhance reliability, and employs a logic-based combination rule to improve interpretability. Specifically, MERIT models the prediction from each sub-view as an opinion with quantified uncertainty under the guidance of the subjective logic theory. Furthermore, a distribution-aware base rate is introduced to enhance performance, particularly in scenarios involving class distribution shifts. Finally, MERIT adopts a feature-specific combination rule to explicitly fuse multi-view predictions, thereby enhancing interpretability. Results have showcased the effectiveness of the proposed MERIT, highlighting the reliability and offering both ad-hoc and post-hoc interpretability. They also illustrate that MERIT can elucidate the significance of each view in the decision-making process for liver fibrosis staging.
Lung Infection Quantification of COVID-19 in CT Images with Deep Learning
Mar 30, 2020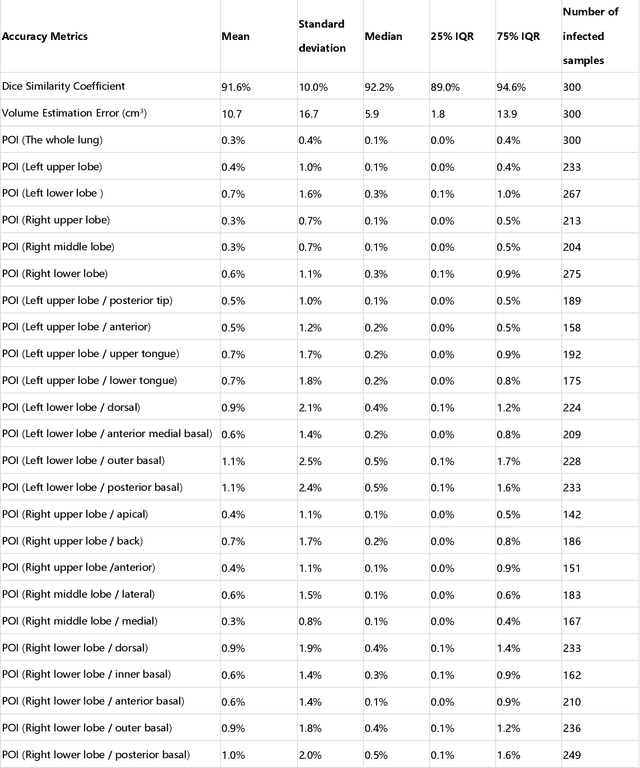
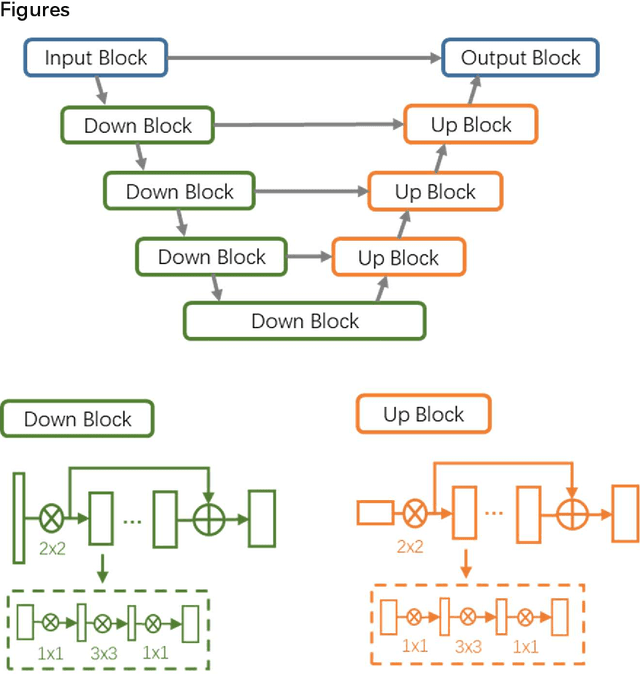
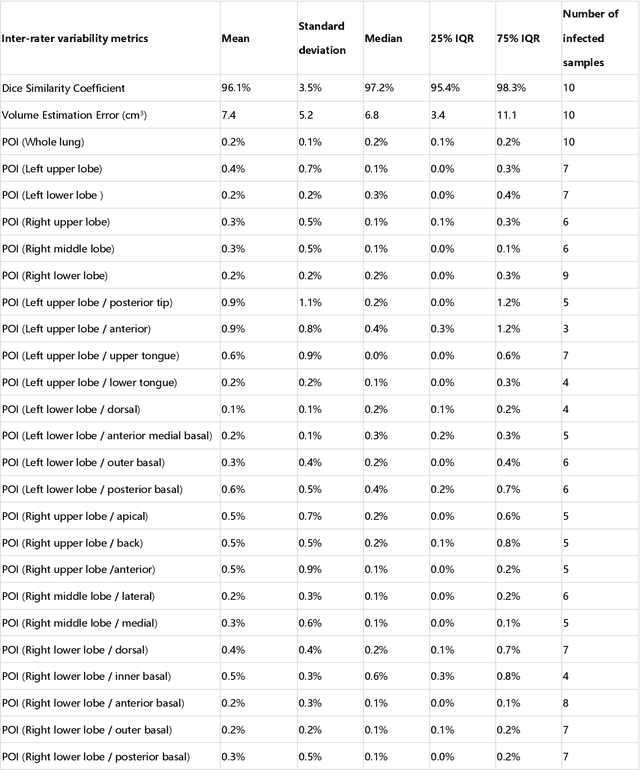
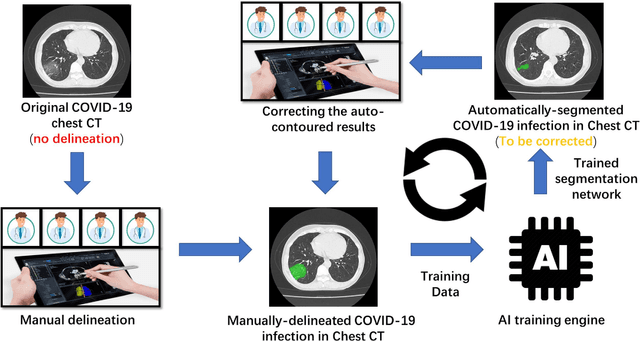
CT imaging is crucial for diagnosis, assessment and staging COVID-19 infection. Follow-up scans every 3-5 days are often recommended for disease progression. It has been reported that bilateral and peripheral ground glass opacification (GGO) with or without consolidation are predominant CT findings in COVID-19 patients. However, due to lack of computerized quantification tools, only qualitative impression and rough description of infected areas are currently used in radiological reports. In this paper, a deep learning (DL)-based segmentation system is developed to automatically quantify infection regions of interest (ROIs) and their volumetric ratios w.r.t. the lung. The performance of the system was evaluated by comparing the automatically segmented infection regions with the manually-delineated ones on 300 chest CT scans of 300 COVID-19 patients. For fast manual delineation of training samples and possible manual intervention of automatic results, a human-in-the-loop (HITL) strategy has been adopted to assist radiologists for infection region segmentation, which dramatically reduced the total segmentation time to 4 minutes after 3 iterations of model updating. The average Dice simiarility coefficient showed 91.6% agreement between automatic and manual infaction segmentations, and the mean estimation error of percentage of infection (POI) was 0.3% for the whole lung. Finally, possible applications, including but not limited to analysis of follow-up CT scans and infection distributions in the lobes and segments correlated with clinical findings, were discussed.